
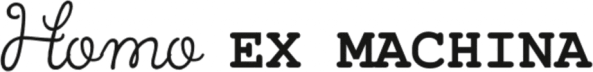
Governing Open-Source AI: A Two-Dimensional Policy Approach
Why adding openness as a second axis can close the gaps in today’s AI regulatory frameworks.

As open-source AI systems approach frontier capabilities, policymakers face a growing challenge: how do we govern powerful, openly available models without stifling innovation?
Today, most AI regulatory frameworks are structured around a single axis—whether it's capabilities (as in California’s SB 1047), levels of risk (as in the EU AI Act), or other organizing principles. Yet these frameworks rarely distinguish between closed and open approaches to AI development. As a result, they struggle to address a growing diversity of release strategies, licensing models, and developer intentions.
At the heart of this issue is the concept of openness—a term still under debate among policymakers, technologists, and researchers. There is no widely agreed-upon definition of what makes an AI model 'open', though they are some tentatives. Some equate openness with accessibility or permissive licensing. Others emphasize the importance of transparency, auditability, and what the Model Openness Framework defines as completeness: the full availability of all components necessary to use, study, and build upon a model.
This debate is not merely academic. In April 2025, a coalition of 30 Members of the European Parliament (MEPs) urged the European Commission to adopt a strict definition of open-source AI within the EU AI Act. They criticized companies like Meta for labeling their AI models as 'open-source' despite imposing significant restrictions, such as prohibiting the use of their Llama series models for training other AI systems and requiring special licenses for commercial applications. The MEPs argued that a diluted definition could undermine the AI Act's implementation, jeopardize citizens' rights, and harm European competitiveness.
Despite its complexity, openness is not yet treated as a formal dimension in most AI policy frameworks. This creates a governance gap—especially as openly shared models become more capable, more widely distributed, and more entangled in high-risk applications.
To address this, I suggest that openness should be considered as a second axis in AI governance, complementing the primary axis used in any given policy framework. Whether the first axis is based on risk, capability, or another organizing principle, adding openness allows us to regulate AI systems in a more nuanced way.
To make it more concrete, this article proposes to illustrate this idea through a two-dimensional governance matrix. As a walk-trough example, I will be using the EU AI Act’s risk classification as the primary axis, and the Model Openness Framework’s three-tier openness classification as the secondary axis.
This is not a complete policy proposal, nor does it attempt to resolve the definitional debates around openness. Instead, this article offers a structured contribution to ongoing discussions. It’s intended for researchers, practitioners, and policymakers working on AI governance, especially those who work on understanding how open models interact with existing regulatory frameworks.
While I do not approach this as a policy expert, I do hope to contribute usefully to the broader discussion.
The State of Open-Source AI Governance
As AI governance becomes a foundational concern in technology policy, the specific challenges of open-source AI remain underdeveloped and underexplored. While open-source AI is rapidly evolving, the policy landscape is still catching up. This section explores why openness matters, the fractures in current definitions, and the resulting governance gap.
What is Openness?
Openness is a concept derived from the open knowledge movement, and more specifically, in the ethos of open science.
While open knowledge holds that all scientific knowledge should be accessible, open science emphasizes transparency, reproducibility, and collaboration throughout the research process. This extends beyond publishing accessible papers—it includes sharing all materials necessary to replicate and build upon results.
Openness, then, draws its core values from both movements, while introducing an essential principle: freedom—the absence of restrictions on access, inspection, modification, or distribution. It reinforces scientific ideals around reproducibility, accountability, and cumulative innovation, while enabling research communities to meaningfully review, critique, reuse, and expand upon prior work.
Openness, at its core, is not an ideological preference—it is an ethical and scientific principle for building responsible, trustworthy knowledge. It fosters democratization, and fuels innovation that is not only reliable, but also oriented toward the public good.
What is Open-Source AI?
The Open Source Definition (OSD), maintained by the Open Source Initiative, outlines ten criteria that software must meet to be considered open-source:
1. Freely Redistributable
2. Source Code Accessible
3. Permissive of Modifications
4. Respectful of Source Code Integrity
5. Non-Discriminatory Toward Individuals or Groups
6. Non-Discriminatory Toward Fields of Use
7. Transferable Without Additional Licensing
8. Independent of Specific Product Bundling
9. Non-Restrictive Toward Other Software
10. Technology-Neutral
However, applying these principles directly to AI systems creates ambiguity. Unlike traditional software, AI models are multimodal systems composed not just of code, but also data (e.g. model weights), and documentation (e.g. model card). This structural complexity opens the door to inconsistent interpretations of what 'open' really means in practice.
As a result, open-source AI often refers to partial releases—shared code or accessible weights—without full transparency. For example, in April 2024, Meta released Llama3 with open weights, but withheld training data, methodology, and model architecture. Yet it still claimed the model was “the most capable openly available LLM to date.” This highlights the problem: without a clear standard, openness becomes a marketing term, not a meaningful policy category. That undermines both public trust and regulatory enforceability.
To bring clarity, the Open Source Initiative proposed a new standard in 2024: the Open Source AI Definition 1.0 (OSAID). It defines open-source AI as systems made available under terms that guarantee four core freedoms—freedom to:
“Use the system for any purpose and without having to ask for permission.”
“Study how the system works and inspect its components.”
“Modify the system for any purpose, including to change its output.”
“Share the system for others to use with or without modifications, for any purpose.”
These freedoms must apply not only to complete systems, but also to individual components—code, data, documentation. Crucially, users must have access to the “preferred form” for making modifications—just as with traditional software under the OSD.
Under this standard, Meta’s Llama3 release would not qualify as open-source AI. And it’s precisely this definition that 30 Members of the European Parliament referenced when urging the European Commission to adopt a stricter open-source definition within the EU AI Act.
Which brings us to the central question: How is open-source AI governed today?
What is the Policy Gap?
State-of-the-art (SOTA) and frontier AI models have made rapid advances in capabilities over the past few years. Yet, most of these systems remain proprietary black boxes, making it difficult to audit, explain, or even robustly assess their true capabilities. In response to this restrictive trend—driven largely by competitive pressures—a growing movement has emerged advocating for openness: companies, research organizations, and individuals sharing models—code, data, and documentation—to advance scientific progress for the broader public good. Encouragingly, according to the U.S. Center for AI Policy (CAIP), “open models have lagged behind closed models by roughly one year in capability”, with the gap actively narrowing.
While the previous sections outlined the benefits of openness, open-source AI also introduce significant safety risks. Misalignment (intentional or accidental), misuse, and the exploitation of dual-use capabilities are harder to control when models are openly accessible. There is little recourse to monitor, restrict, or rescind their use once they are distributed. Although systematic reviews suggest that the benefits of openness outweigh the risks1, striking the right balance remains one of the most pressing challenges for both the AI research community and policymakers. As an early attempt at governance, AI labs have voluntarily adopted safety plans—an approach the U.S. CAIP recommends policymakers formalize through legal accountability.
For those interested in deepening their understanding of AI labs safety plans, I recommend this insightful article:

Still, the practice of open-washing—partially sharing elements of an AI system while restricting others, and claiming openness—remains widespread. Without a clear legal standard defining open-source AI, regulations struggle to draw a meaningful line between 'closed' and 'open' systems, often defaulting to a binary view that fails to capture critical nuances. Moreover, transparency initiatives accompanying model releases often lack completeness, leading to inconsistent disclosures between developers.
Globally, this fragmented approach introduces strategic and geopolitical risks. For example, while DeepSeek’s open models have been widely adopted by U.S. users due to their state-of-the-art performance at a fraction of the cost of proprietary alternatives, concerns have surfaced around potential mass data exfiltration. Simultaneously, China's open-source AI community has exhibited heavy reliance on Meta’s Llama models having allegedly been adapted for defense-related applications—despite restrictions in Meta’s licensing terms—sparking contentious policy debates.
These developments raise an urgent question: Should open-source AI systems be governed under the same frameworks as closed models—or does their distinctive nature demand a fundamentally different approach?
The Model Openness Framework
This section presents selected key concepts from the following paper:
The Model Openness Framework (MOF) is a three-tier classification system developed by The Linux Foundation to assess the openness of AI model releases. It evaluates models based on completeness, transparency, and licensing. In doing so, the MOF provides an objective foundation for defining what it means for an AI system to be open, rooted in the principles of open science.
The MOF goes beyond the Open Source AI Definition (OSAID), which it helped inspire. While the OSAID defines openness in terms of four core freedoms, the MOF extends this concept through completeness—the idea that openness must apply to all components of a model release. For each tier, the MOF specifies the code, data, and documentation components that must be shared under open licenses, ensuring consistency and comparability across different releases.
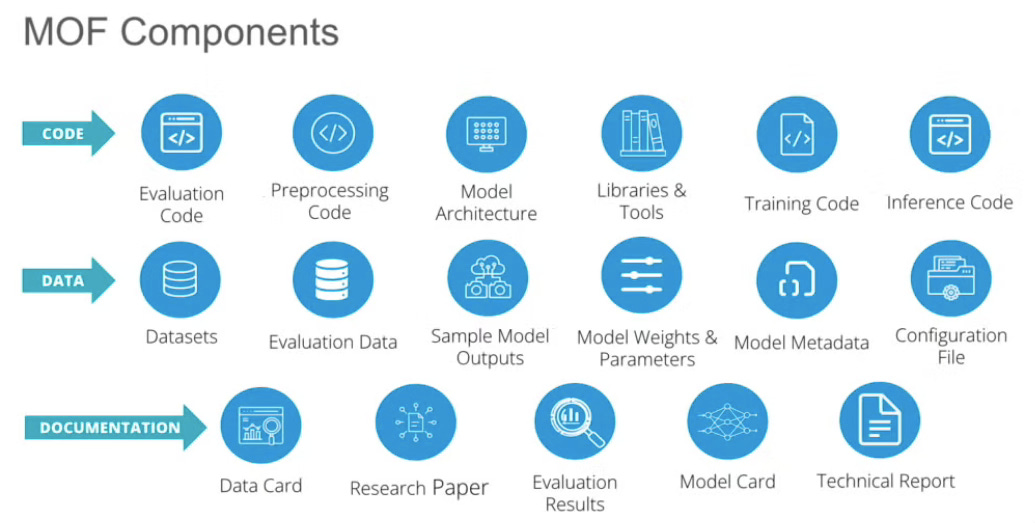
How does the MOF work?
The MOF turns the abstract concept of openness into a tangible framework—one that model developers can follow and model users can evaluate. It lays out exactly which components are required at each level of openness and under which licensing terms they must be released.
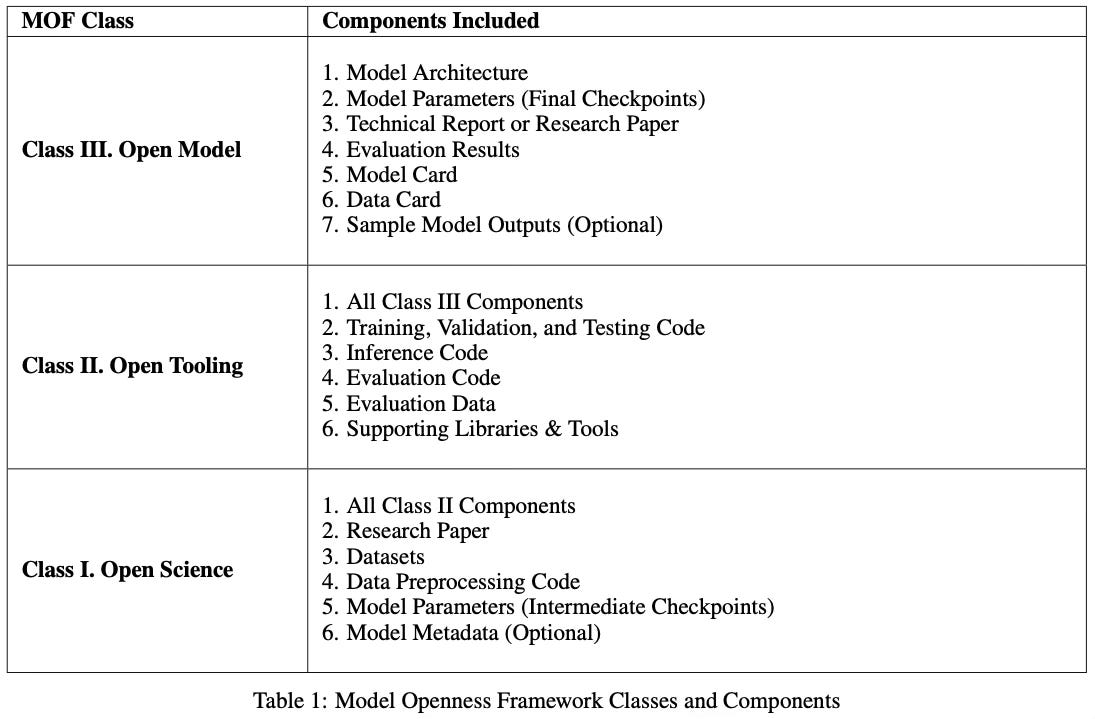
The three tiers of the MOF are described below:
“Class III – Open Model: The minimum bar for entry, Class III requires the public release of the core model (architecture, parameters, basic documentation) under open licenses. This allows model consumers to use, analyze, and build on the model, but limits insight into the development process.”
“Class II – Open Tooling: Building on Class III, this tier includes the full suite of code used to train, evaluate, and run the model, plus key datasets. Releasing these components enables the community to better validate the model and investigate issues. It is a significant step towards reproducibility.”
“Class I – Open Science: The apex, Class I entails releasing all artifacts following open science principles. In addition to the Class II components, it includes the raw training datasets, a thorough research paper detailing the entire model development process, intermediate checkpoints, log files, and more. This provides unparalleled transparency into the end-to-end development pipeline, empowering collaboration, auditing, and cumulative progress.”
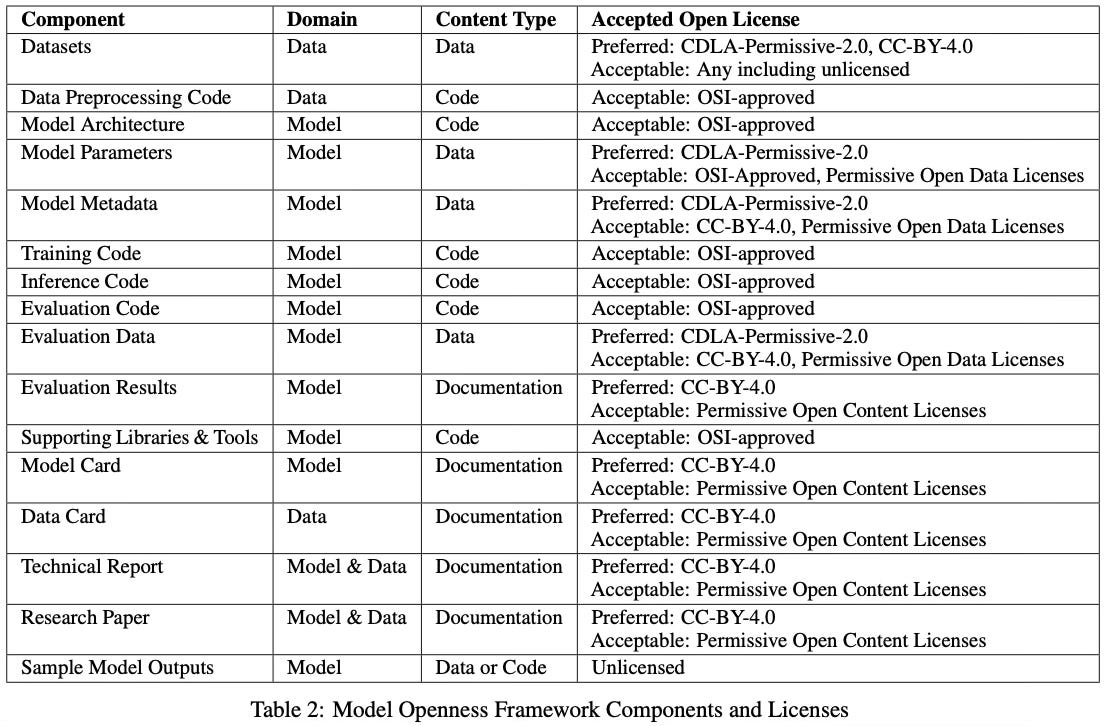
The MOF is accompanied by the Model Openness Tool (MOT), an open-source platform that allows model developers to benchmark their releases against MOF criteria. The MOT leaderboard updates automatically when new models are submitted, verifying component availability and licensing compliance.
At the time of writing, only one model had qualified for Class I.
Why is the MOF useful for policymaking?
Although the MOF was not designed with regulatory enforcement in mind, it offers a policy-agnostic classification system that can complete any AI governance framework. By standardizing how openness is measured, the MOF reduces ambiguity, facilitates compliance, and supports more consistent disclosures—without prescribing any specific policy outcomes.
Its utility lies in this complementarity. The MOF does not attempt to address AI safety, performance testing, red-teaming, or other operational concerns like provenance or copyright. Nor does it currently extend to all types of machine learning processes—reinforcement learning remains out of scope. But by providing a transparent and replicable taxonomy of openness, the MOF can serve as a valuable companion to regulatory systems that do address those issues.
In short, the MOF is not a governance solution on its own—but it can strengthen governance when used alongside one.
A Two-Dimensional Governance Matrix
Current AI policy frameworks—like the EU AI Act—tend to treat openness as an afterthought. Their regulatory logic is largely binary: they offer clear rules for closed, proprietary systems, while remaining vague toward systems labeled as 'open', without settling on a clear definition of the term. This creates a two-speed regulatory environment, where oversight is strong for some models, and practically nonexistent for others. As discussed earlier, this regulatory gap introduces potential safety risks, as open-source AI systems increasingly fall into a blind spot of governance.
To address this imbalance, I propose a two-dimensional governance approach. Rather than replacing existing frameworks, this model builds on them—by introducing openness as a complementary axis of regulation.
Specifically, I suggest using the Model Openness Framework as a second dimension alongside whatever primary axis a policy framework employs—whether that axis is based on risk, capability, or something else. In doing so, policymakers can move beyond one-size-fits-all rules, toward a more adaptive model of oversight.

To make this more tangible, the remainder of this article explores what this could look like in practice, using the EU AI Act’s risk classification as the primary axis and the MOF’s openness tiers as the secondary.
The EU AI Act’s Risk Classification
The EU AI Act is a comprehensive legal framework for artificial intelligence. It seeks to foster trustworthy AI by applying a risk-based regulatory approach, categorizing systems based on the potential harm they may pose to individuals, society, or fundamental rights.
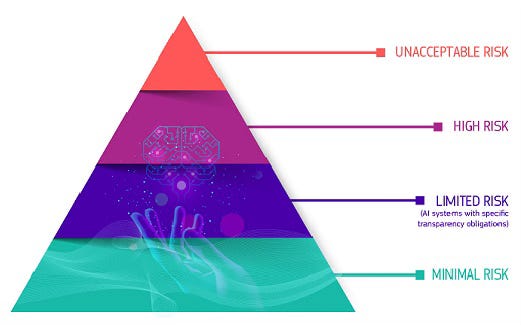
The Act defines four distinct risk categories—unacceptable, high, limited, and minimal—each triggering different regulatory obligations. While systems in the unacceptable category are outright banned, only high-risk systems face significant regulatory scrutiny. The remainder are subject to minimal or no intervention.
The four levels of risk for AI systems are defined as follows:
Unacceptable Risk: These systems are outright banned due to clear, systemic threats. Prohibited practices include manipulative AI, exploitative targeting of vulnerable groups, social scoring, real-time biometric surveillance in public, and emotion recognition in sensitive contexts.
High Risk: These systems are permitted but tightly regulated. They include AI used in critical infrastructure, education, healthcare, employment, law enforcement, border control, and justice. Requirements include rigorous risk management, transparency, human oversight, and data quality standards.
Limited Risk: These systems raise moderate concerns, mainly around transparency. The Act mandates disclosures—for example, users must know when they’re interacting with a chatbot or viewing AI-generated content, including deepfakes.
Minimal Risk: Most AI systems fall here, such as spam filters or game AIs. These are considered low-impact and are not subject to regulatory requirements.
Importantly, the EU AI Act exempts open-source AI systems from most obligations, unless they fall into the high-risk or unacceptable risk categories. Specifically, Article 2 (12) states:
“This Regulation does not apply to AI systems released under free and open-source licenses, unless they are placed on the market or put into service as high-risk AI systems or as an AI system that falls under Article 5 or 50.”
This means that while most open-source AI are excluded from the Act’s reach, frontier AI, because of their dual-use capabilities—are still in scope.
Building the Governance Matrix
The introduction of openness as a second axis becomes especially critical when considering frontier AI—models that not only drive cutting-edge scientific discoveries but also raise some of the most urgent governance challenges. Heavy-handed regulation of frontier open-source AI risks stifling innovation and widening the gap between public research efforts and proprietary development, ultimately concentrating powerful AI capabilities in the hands of a few.
By moving from a unidimensional to a bidimensional policy framework, however, regulators gain a more finely grained canvas for intervention. Considering openness alongside risk allows regulatory responses to be better calibrated—smoother, more adaptive, and more proportionate to both the model’s capabilities and the nature of its release.
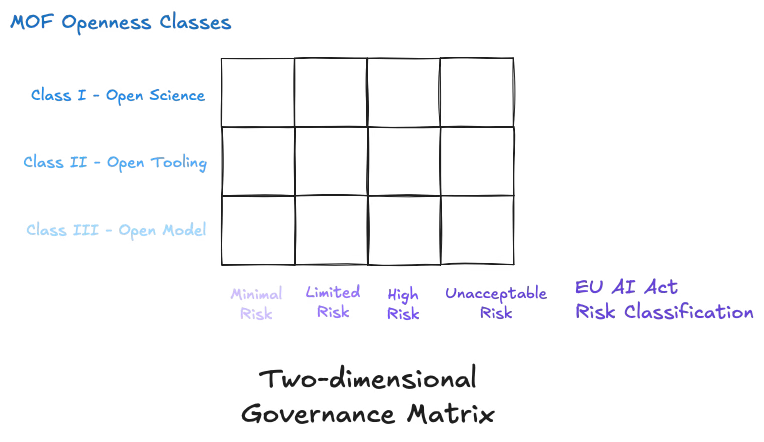
As illustrated in the two matrices below, the EU AI Act exempts minimal-risk systems from oversight and bans unacceptable-risk systems. In the intermediate categories—limited risk and high risk—introducing openness as a secondary axis allows for more differentiated approaches to open-source AI governance.
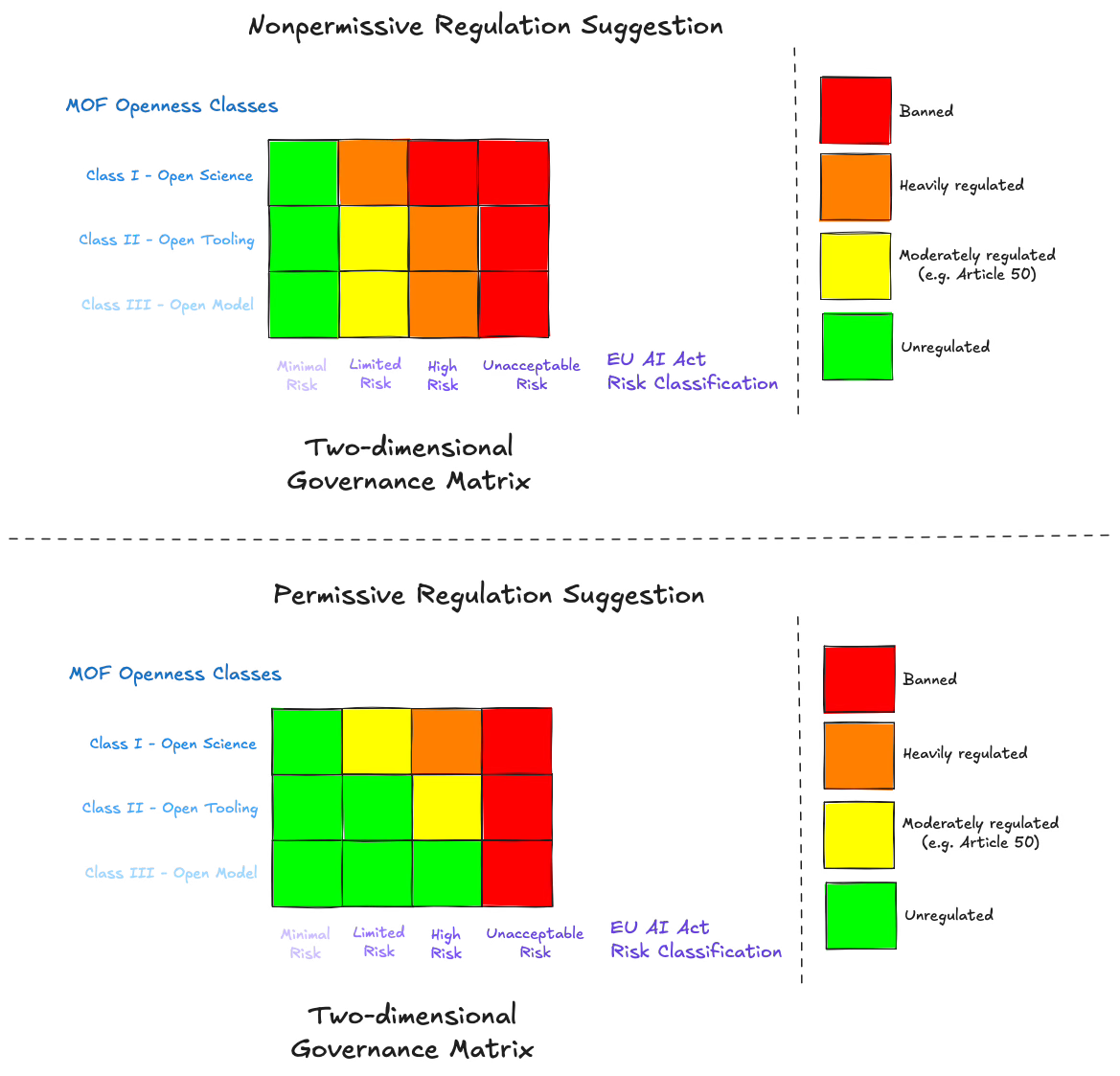
Mapping high-risk open-source AI onto frontier open-source AI for the sake of illustration, two regulatory strategies could be envisioned (among others):
Nonpermissive Regulation: Class III and Class II models would be regulated on par with closed frontier AI systems, while Class I models—those achieving full openness under the MOF—would be banned. This approach largely mirrors the EU AI Act’s current handling of high-risk systems.
Permissive Regulation: Class III models would be unregulated, Class II models would be moderately regulated (for example, subject to obligations similar to those for limited-risk systems under Article 50 of the EU AI Act), and Class I models would remain banned. This strategy would more actively promote innovation within the open science ethos while still imposing guardrails to mitigate safety risks.
Beyond static policy design, a two-dimensional framework also opens the door to dynamic governance. Policymakers could prepare matrix configurations contingent on changes in the AI governance environment—for instance, automatically shifting regulatory requirements following major international agreements, the enactment of complementary legislation, or the crossing of predefined risk thresholds.
Next Steps and Open Questions
Toward Adaptive and Dynamic Governance
Opting for a bidimensional policy framework not only gives policymakers greater flexibility when designing regulations—it also offers a finer-grained governance canvas, particularly in the case of open-source AI, where innovation, competitiveness, and geostrategic tensions intersect. The ability to build more adaptable and even dynamic regulatory systems is a promising direction, providing policymakers with tools to respond more quickly and precisely to changes in the AI ecosystem.
Historically, AI governance has often been criticized for its slowness relative to the accelerating pace of AI development. By designing frameworks that anticipate environmental shifts—triggering predefined policy modifications as conditions evolve—policymakers could remain much closer to the center of technological change, rather than trailing behind it.
Open Questions for Policymakers and Researchers
While complementing existing frameworks with a policy-agnostic second axis—such as openness—offers an intriguing path forward, it remains a conceptual proposal requiring further research. Key questions must be addressed: What criteria, beyond openness, could serve as effective secondary axes? Could dimensions like compute thresholds, model capabilities, or access controls meaningfully structure a governance matrix? How could regulatory mechanisms operationalize such an approach, and what enforcement challenges are foreseeable?
Additionally, the idea of introducing a third dimension—moving from a matrix to a 3D tensor—merits exploration. Would this create a richer and more precise regulatory framework, or would it introduce unnecessary complexity that risks paralyzing policy processes?
Reflections
While I do not have the answers to these questions—nor the pretension of being able to answer them—I hope that the ideas I have shared in this article can help enrich the discussion. My aim is to contribute a few useful perspectives to the broader conversation, in the hope that they may prove relevant for the future of AI governance.
Acknowledgments
This article was written as part of the Spring 2025 BlueDot Impact AI Governance Course, as an end-of-course project.
I would like to personally thank Vivianne Manlai, Alexandra Ivan, Alexandre Karim Howard, and Muhammad Aliyu for their invaluable support and the inspiring discussions I had the pleasure of sharing with them throughout the course.